Suuret kielimallit tuottavat jokaiselle mahdolliselle seuraavalle tokenille todennäköisyyden. Niillä voidaan tunnistaa milloin valittu token ei ole todennäköinen jatko edellisille tokeneille.
Tein Cursorilla koodin, joka tulostaa todennäköisyydet vastaukseen. Kielimallina käytin LM Studion kautta Gemma 4:ä (31B QAT Q4_0).
Kun syötteeksi annetaan "Kuka kirjoitti teoksen 'Siniset varjot' vuonna 1954?", saadaan vastaus: "Teoksen Siniset varjot (1954) kirjoitti Sirkka-Liisa Åhlström." Oikeasti teosta ei ole olemassakaan.
Kuvan ryhmissä on ylimpänä valittu token ja sen alapuolella 4 muuta todennäköisintä. Korostetut tokenit on valittu, vaikka niiden todennäköisyys on alle 50%.
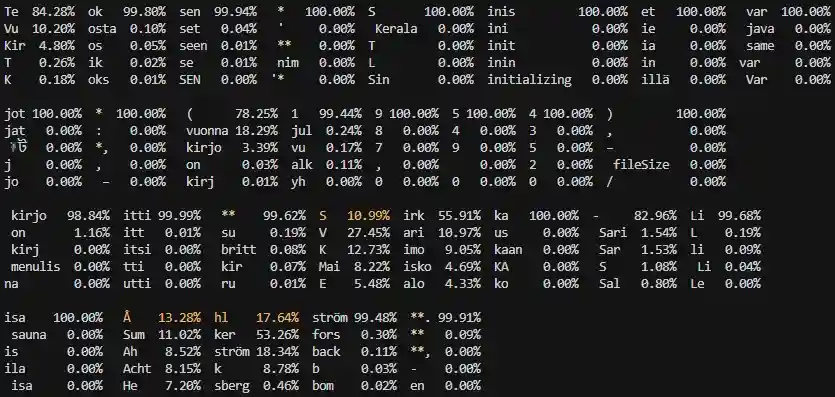
Kirjailijan nimen aloittavaksi tokeniksi valittiin S. Kaikkien vaihtoehtojen todennäköisyydet olivat alhaisia. Havainto auttaa hallusinaation tunnistamisessa. Myös sukunimen kohdalla todennäköisyys oli alhainen. Tokenin valinnassa on satunnaisuutta toistuvuuden estämiseksi, minkä takia todennäköisintä tokenia (Å:n jälkeen ker) ei aina valita.
Todennäköisyyksistä ei voi suoraan vetää johtopäätöstä hallusinoinnista, mutta se on tyhjää parempi indikaattori. Olisi hyvä, jos ChatGPT:t ja vastaavat ilmoittaisivat käyttäjälle, kun tokenin todennäköisyys on alhainen. Käyttäjä pystyisi paremmin arvioimaan vastauksen luotettavuutta.
Lopuksi vielä käytetty koodi. Vaatii OpenAI API -yhteensopivan rajapinnan, kuten LM Studion.
"""
Yhdistää LM Studioon ja näyttää generoidun tekstin token-todennäköisyydet.
Vaatimukset:
- LM Studio käynnissä (oletus: http://localhost:1234)
- Malli ladattu ja valittu LM Studiossa
- pip install openai wcwidth
Huom: logprobs vaatii LM Studion /v1/responses -endpointin (Open Responses).
"""
import json
import math
import sys
import urllib.request
from dataclasses import dataclass
import wcwidth
from openai import OpenAI
BASE_URL = "http://localhost:1234/v1"
INPUT = "Kuka oli presidentti Suomessa pisimpään?"
TOP_LOGPROBS = 5
MAX_OUTPUT_TOKENS = 64
TOKENS_PER_ROW = 8
LOW_PROB_THRESHOLD = 0.5
COLOR_LOW_PROB = "\033[93m"
COLOR_RESET = "\033[0m"
@dataclass
class TokenPosition:
token: str
probability: float
alternatives: list[tuple[str, float]]
def get_loaded_model() -> str:
models_url = BASE_URL.rstrip("/") + "/models"
with urllib.request.urlopen(models_url, timeout=5) as response:
data = json.loads(response.read().decode())
return data["data"][0]["id"]
def fetch_token_probabilities(model: str) -> list[TokenPosition]:
client = OpenAI(base_url=BASE_URL, api_key="lm-studio")
response = client.responses.create(
model=model,
input=INPUT,
include=["message.output_text.logprobs"],
top_logprobs=TOP_LOGPROBS,
max_output_tokens=MAX_OUTPUT_TOKENS,
reasoning={"effort": "none"},
)
message = next(item for item in response.output if item.type == "message")
return [
TokenPosition(
token=entry.token,
probability=math.exp(entry.logprob),
alternatives=[
(candidate.token, math.exp(candidate.logprob))
for candidate in entry.top_logprobs
if candidate.token != entry.token
],
)
for entry in message.content[0].logprobs
]
def visible_width(text: str) -> int:
width = wcwidth.wcswidth(text)
return width if width >= 0 else len(text)
def pad_right(text: str, width: int) -> str:
padding = width - visible_width(text)
return text + " " * padding if padding > 0 else text
def pad_left(text: str, width: int) -> str:
padding = width - visible_width(text)
return " " * padding + text if padding > 0 else text
def format_token_line(
token: str,
probability: float,
token_column_width: int,
prob_column_width: int,
) -> str:
return (
pad_right(token, token_column_width)
+ " "
+ pad_left(f"{probability:.2%}", prob_column_width)
)
def highlight(text: str) -> str:
return f"{COLOR_LOW_PROB}{text}{COLOR_RESET}"
def cell_lines(position: TokenPosition) -> list[tuple[str, float]]:
lines = [(position.token.replace("\n", "\\n"), position.probability)]
lines.extend(
(token.replace("\n", "\\n"), probability)
for token, probability in position.alternatives
)
return lines
def column_widths(
cells: list[list[tuple[str, float]]],
) -> tuple[list[int], list[int], list[int]]:
token_widths = [
max(visible_width(token) for token, _ in cell)
for cell in cells
]
prob_widths = [
max(len(f"{probability:.2%}") for _, probability in cell)
for cell in cells
]
total_widths = [
token_widths[i] + 1 + prob_widths[i]
for i in range(len(cells))
]
return token_widths, prob_widths, total_widths
def print_token_grid(positions: list[TokenPosition]) -> None:
for row_start in range(0, len(positions), TOKENS_PER_ROW):
row = positions[row_start : row_start + TOKENS_PER_ROW]
cells = [cell_lines(position) for position in row]
token_widths, prob_widths, col_widths = column_widths(cells)
row_count = max(len(cell) for cell in cells)
for line_index in range(row_count):
columns = []
for col_index, cell in enumerate(cells):
if line_index >= len(cell):
columns.append(" " * col_widths[col_index])
continue
token, probability = cell[line_index]
line = format_token_line(
token,
probability,
token_widths[col_index],
prob_widths[col_index],
)
if line_index == 0 and probability < LOW_PROB_THRESHOLD:
line = highlight(line)
columns.append(line)
print(" ".join(columns))
print()
def print_results(positions: list[TokenPosition]) -> None:
print("=" * 60)
print("MALLIN VASTAUS")
print("=" * 60)
print("".join(
highlight(position.token)
if position.probability < LOW_PROB_THRESHOLD
else position.token
for position in positions
))
print()
print("=" * 60)
print("TOKEN-TODENNÄKÖISYYDET")
print("=" * 60)
print()
print_token_grid(positions)
def main() -> None:
if hasattr(sys.stdout, "reconfigure"):
sys.stdout.reconfigure(encoding="utf-8")
model = get_loaded_model()
print(f"Käytetään mallia: {model}\n")
print_results(fetch_token_probabilities(model))
if __name__ == "__main__":
main()